前言 Oracle里存储的结构化数据导出到Hadoop体系做离线计算是一种常见数据处置手段。近期有场景需要做Oracle到Kafka的实时导入,这里以此案例进行介绍。
ogg即Oracle GoldenGate是Oracle的同步工具,本文讲如何配置ogg以实现Oracle数据库增量数据实时同步到kafka中,其中同步消息格式为json。
下面是我的源端和目标端的一些配置信息:
-
版本
OGG版本
ip
主机名
源端
OracleRelease 11.2.0.1.0
Oracle GoldenGate 11.2.1.0.3 for Oracle on Linux x86-64
192.168.23.167
cdh01
目标端
kafka_2.11-0.11.0.1
Oracle GoldenGate for Big Data 12.3.0.1.0 on Linux x86-64
192.168.23.168
cdh02
下载 注意:源端和目标端的文件不一样,目标端需要下载Oracle GoldenGate for Big Data,源端需要下载Oracle GoldenGate for Oracle具体下载方法见最后的附录截图。
目标端在这里 查询下载,源端在旧版本 查询下载。
源端(Oracle)配置 注意:源端是创建了oracle用户且安装了oracle数据库,oracle环境变量之前都配置好了
(后面只要涉及到源端均在oracle用户下操作)
解压 先建立ogg目录
1 2 mkdir -p /oracledata/data/ogg unzip Oracle GoldenGate_11.2.1.0.3.zip
解压后得到一个tar包,再解压这个tar
1 tar xf fbo_ggs_Linux_x64_ora11g_64bit.tar -C /oracledata/data/ogg
配置ogg环境变量 1 2 3 export OGG_HOME=/oracledata/data/ogg export LD_LIBRARY_PATH=$ORACLE_HOME/lib:/usr/lib export PATH=$OGG_HOME:$PATH
使之生效
测试一下ogg命令
如果命令成功即可进行下一步,不成功请检查前面的步骤。
oracle打开归档模式 1 2 # 以DBA身份连接数据库 sqlplus / as sysdba
执行下面的命令查看当前是否为归档模式
若显示如下,则说明当前未开启归档模式
1 2 3 4 5 Database log mode No Archive Mode Automatic archival Disabled Archive destination USE_DB_RECOVERY_FILE_DEST Oldest online log sequence 12 Current log sequence 14
手动打开即可
1 2 3 4 5 6 7 8 9 10 # 立即关闭数据库 SQL> shutdown immediate # 启动实例并加载数据库,但不打开 SQL> startup mount # 更改数据库为归档模式 SQL> alter database archivelog; # 打开数据库 SQL> alter database open; # 启用自动归档 SQL> alter system archive log start;
再执行一下命令查看当前是否为归档模式
1 2 3 4 5 6 Database log mode Archive Mode Automatic archival Enabled Archive destination USE_DB_RECOVERY_FILE_DEST Oldest online log sequence 12 Next log sequence to archive 14 Current log sequence 14
可以看到为Enabled,则成功打开归档模式。
Oracle打开日志相关 OGG基于辅助日志等进行实时传输,故需要打开相关日志确保可获取事务内容,通过下面的命令查看该状态
1 SQL> select force_logging, supplemental_log_data_min from v$database ;
1 2 3 FORCE_ SUPPLEMENTAL_LOG - ----- ---------------- NO NO
若为NO,则需要通过命令修改
1 2 SQL> alter database force logging; SQL> alter database add supplemental log data;
再查看一下为YES即可
1 SQL> select force_logging, supplemental_log_data_min from v$database ;
1 2 3 FORCE_ SUPPLEMENTAL_LOG - ----- ---------------- YES YES
上述操作只是开启了最小补充日志,如果要抽取全部字段需要开启全列补充日志,否则值为null的字段不会在抽取日志中显示!!!
补充日志开启命令参考:https://blog.csdn.net/aaron8219/article/details/16825963
注:开启全列补充日志会导致磁盘快速增长,LGWR进程繁忙,不建议使用。大家可根据自己的情况使用。
查看数据库是否开启了全列补充日志
1 2 3 4 5 SQL> select supplemental_log_ data_all from v$database; SUPPLE ------ NO
若未开启可以通过以下命令开启。
1 2 3 4 5 6 7 8 9 SQL> alter database add supplemental log data(all) columns; Database altered. SQL> select supplemental_log_ data_all from v$database; SUPPLE ------ YES
oracle创建复制用户 1 mkdir -p /oracledata/ data/tablespace/ dbsrv2
然后执行下面sql
1 2 3 4 5 6 7 8 SQL> create tablespace oggtbs datafile '/oracledata/data/tablespace/dbsrv2/oggtbs01.dbf' size 1000M autoextend on; 控制台显示的内容:Tablespace created. SQL> create user ogg identified by 123456 default tablespace oggtbs; 控制台显示的内容:User created. SQL> grant dba to ogg; 控制台显示的内容:Grant succeeded.
OGG初始化 1 2 3 4 cd $OGG_HOME ggsci # 创建目录 GGSCI (cdh01) 1> create subdirs
控制台显示的内容如下:
1 2 3 4 5 6 7 8 9 10 11 Creating subdirectories under current directory /oracledata/data/ogg Parameter files /oracledata/data/ogg/dirprm: created Report files /oracledata/data/ogg/dirrpt: created Checkpoint files /oracledata/data/ogg/dirchk: created Process status files /oracledata/data/ogg/dirpcs: created SQL script files /oracledata/data/ogg/dirsql: created Database definitions files /oracledata/data/ogg/dirdef: created Extract data files /oracledata/data/ogg/dirdat: created Temporary files /oracledata/data/ogg/dirtmp: created Stdout files /oracledata/data/ogg/dirout: created
Oracle创建测试表 创建一个用户,在该用户下新建测试表,用户名、密码、表名均为 test_ogg。
1 2 3 4 5 sqlplus / as sysdba SQL> create user test_ogg identified by test_ogg default tablespace users; SQL> grant dba to test_ogg; SQL> conn test_ogg/test_ogg; SQL> create table test_ogg(id int,name varchar(20),sex varchar(4),primary key(id));
目标端(kafka)配置 1 2 3 mkdir -p /data/apps/ogg unzip OGG_BigData_12.3.0 .1.0 _Release.zip tar xf ggs_Adapters_Linux_x64.tar -C /data/apps/ogg
环境变量 1 2 3 4 5 6 7 export JAVA_HOME=/opt/java /jdk1.8.0_211 export PATH=$JAVA_HOME/bin :$PATHexport CLASSPATH=.:$JAVA_HOME/lib /dt .jar :$JAVA_HOME /lib /tools .jar export OGG_HOME=/data/apps /ogg export LD_LIBRARY_PATH=$JAVA_HOME/jre /lib/amd 64:$JAVA_HOME/jre/lib /amd64 /server :$JAVA_HOME /jre /lib /amd64 /libjsig .so :$JAVA_HOME /jre /lib /amd64 /server /libjvm .so :$OGG_HOME /lib export PATH=$OGG_HOME: $PATH
同样测试一下ogg命令
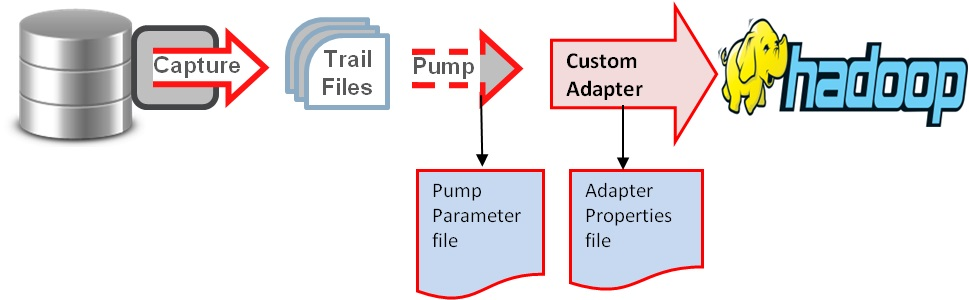
初始化目录 OGG源端配置 Oracle实时传输到Hadoop集群(HDFS,Hive ,Kafka等)的基本原理如图:
配置OGG的全局变量 1 2 3 4 GGSCI (cdh01) 1> dblogin userid ogg password 123456 控制台显示的内容:Successfully logged into database. GGSCI (cdh01) 2> edit param ./globals
然后和用vim编辑一样添加
配置管理器mgr 1 GGSCI (cdh01 ) 3 > edit param mgr
然后和用vim编辑一样添加
1 2 3 4 PORT 7809 DYNAMICPORTLIST 7810-7909 AUTORESTART EXTRACT *,RETRIES 5,WAITMINUTES 3 PURGEOLDEXTRACTS ./dirdat/*,usecheckpoints, minkeepdays 3
说明:PORT即mgr的默认监听端口;
DYNAMICPORTLIST动态端口列表,当指定的mgr端口不可用时,会在这个端口列表中选择一个,最大指定范围为256个;
AUTORESTART重启参数设置表示重启所有EXTRACT进程,最多5次,每次间隔3分钟;
PURGEOLDEXTRACTS即TRAIL文件的定期清理
添加复制表 1 2 3 4 5 6 GGSCI (cdh01) 4> add trandata test_ogg.test_ogg 控制台显示的内容:Logging of supplemental redo data enabled for table TEST_OGG.TEST_OGG. GGSCI (cdh01) 5> info trandata test_ogg.test_ogg 控制台显示的内容:Logging of supplemental redo log data is enabled for table TEST_OGG.TEST_OGG. 控制台显示的内容:Columns supplementally logged for table TEST_OGG.TEST_OGG: ID
1 GGSCI (cdh01 ) 6 > edit param extkafka
然后和用vim编辑一样添加
1 2 3 4 5 6 7 8 9 10 extract extkafkadynamicresolution SETENV "dbsrv2" )SETENV "american_america.AL32UTF8" )GETUPDATEBEFORES NOCOMPRESSDELETES NOCOMPRESSUPDATES userid ogg,password 123456exttrail /oracledata/data/ogg/dirdat/totable test_ogg.test_ogg;
说明:
第一行指定extract进程名称;
dynamicresolution动态解析;
SETENV设置环境变量,这里分别设置了Oracle数据库以及字符集;
userid ogg,password 123456即OGG连接Oracle数据库的帐号密码,这里使用2.5中特意创建的复制帐号;exttrail定义trail文件的保存位置以及文件名,注意这里文件名只能是2个字母,其余部分OGG会补齐;
table即复制表的表名,支持*通配,必须以;结尾
添加extract进程:
1 2 GGSCI (cdh01) 7 > add extract extkafka,tranlog,begin now 控制台显示的内容:EXTRACT added.
(注:若报错
1 ERROR: Could not create checkpoint file /opt/ogg/dirchk/EXTKAFKA.cpe (error 2, No such file or directory).
执行下面的命令再重新添加即可。
)
添加trail文件的定义与extract进程绑定:
1 2 GGSCI (cdh01) 8> add exttrail /oracledata/data/ogg/dirdat/to ,extract extkafka 控制台显示的内容:EXTTRAIL added.
配置pump进程 pump进程本质上来说也是一个extract,只不过他的作用仅仅是把trail文件传递到目标端,配置过程和extract进程类似,只是逻辑上称之为pump进程
1 GGSCI (cdh01 ) 9 > edit param pukafka
然后和用vim编辑一样添加
1 2 3 4 5 6 7 extract pukafka passthru dynamicresolution userid ogg,password 123456 rmthost 192.168 .23 .168 mgrport 7809 rmttrail /data/apps/ogg/dirdat/to table test_ogg.test_ogg;
说明:
第一行指定extract进程名称;
passthru即禁止OGG与Oracle交互,我们这里使用pump逻辑传输,故禁止即可;
dynamicresolution动态解析;
userid ogg,password ogg即OGG连接Oracle数据库的帐号密码
rmthost和mgrhost即目标端(kafka)OGG的mgr服务的地址以及监听端口;
rmttrail即目标端trail文件存储位置以及名称。(注意,这里很容易犯错!!!注意是目标端的路径!!!)
分别将本地trail文件和目标端的trail文件绑定到extract进程:
1 2 3 4 GGSCI (cdh01) 10> add extract pukafka,exttrailsource /oracledata/data/ogg/dirdat/to 控制台显示的内容:EXTRACT added. GGSCI (cdh01) 11> add rmttrail /data/apps/ogg/dirdat/to ,extract pukafka 控制台显示的内容:RMTTRAIL added.
配置defgen文件 Oracle与MySQL,Hadoop集群(HDFS,Hive,kafka等)等之间数据传输可以定义为异构数据类型的传输,故需要定义表之间的关系映射,在OGG命令行执行:
1 GGSCI (cdh01 ) 12 > edit param test_ogg
然后和用vim编辑一样添加
1 2 3 defsfile /oracledata/ data/ogg/ dirdef/test_ogg.test_ogg userid ogg,password 123456 table test_ogg.test_ogg;
退出GGSCI
进行OGG主目录下执行以下命令
1 2 cd $OGG_HOME ./defgen paramfile dirprm/test_ogg.prm
输出以下内容则执行成功。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 *********************************************************************** Oracle GoldenGate Table Definition Generator for Oracle Version 11.2.1.0.3 14400833 OGGCORE_11.2.1.0.3_PLATFORMS_120823.1258 Linux, x64, 64bit (optimized), Oracle 11g on Aug 23 2012 16:58:29 Copyright (C) 1995, 2012, Oracle and/or its affiliates. All rights reserved. Starting at 2018-05-23 05:03:04 *********************************************************************** Operating System Version: Linux Version #1 SMP Wed Apr 12 15:04:24 UTC 2017, Release 3.10.0-514.16.1.el7.x86_64 Node: ambari.master.com Machine: x86_64 soft limit hard limit Address Space Size : unlimited unlimited Heap Size : unlimited unlimited File Size : unlimited unlimited CPU Time : unlimited unlimited Process id: 13126 *********************************************************************** ** Running with the following parameters ** *********************************************************************** defsfile /opt/ogg/dirdef/test_ogg.test_ogg userid ogg,password *** table test_ogg.test_ogg; Retrieving definition for TEST_OGG.TEST_OGG Definitions generated for 1 table in /oracledata/data/ogg/dirdef/test_ogg.test_ogg
将生成的/oracledata/data/ogg/dirdef/test_ogg.test_ogg发送的目标端ogg目录下的dirdef里:
1 scp -r /oracledata/data/ogg/dirdef/test_ogg.test_ogg root@cdh02:/data/apps/ogg/dirdef/
OGG目标端配置 开启kafka服务 1 2 3 4 # 开启Zookeeper /data/apps/apache-zookeeper-3.5.5-bin/bin/zkServer.sh start # 开启Kafka /data/apps/kafka_2.11-0.11.0.1/bin/kafka-server-start.sh -daemon config/server.properties
配置管理器mgr 1 2 3 4 5 GGSCI (cdh02) 1> edit param mgr PORT 7809 DYNAMICPORTLIST 7810-7909 AUTORESTART EXTRACT *,RETRIES 5,WAITMINUTES 3 PURGEOLDEXTRACTS ./dirdat/*,usecheckpoints, minkeepdays 3
配置checkpoint checkpoint即复制可追溯的一个偏移量记录,在全局配置里添加checkpoint表即可。
1 2 GGSCI (cdh02) 2> edit param ./GLOBALS CHECKPOINTTABLE test_ogg.checkpoint
配置replicate进程 1 2 3 4 5 6 7 GGSCI (cdh02) 3> edit param rekafka REPLICAT rekafka sourcedefs /data/apps/ogg/dirdef/test_ogg.test_ogg TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka.props REPORTCOUNT EVERY 1 MINUTES, RATE GROUPTRANSOPS 10000 MAP test_ogg.test_ogg, TARGET test_ogg.test_ogg;
说明:
REPLICATE rekafka定义rep进程名称;
sourcedefs即在4.6中在源服务器上做的表映射文件;
TARGETDB LIBFILE即定义kafka一些适配性的库文件以及配置文件,配置文件位于OGG主目录下的dirprm/kafka.props;
REPORTCOUNT即复制任务的报告生成频率;
GROUPTRANSOPS为以事务传输时,事务合并的单位,减少IO操作;
MAP即源端与目标端的映射关系
配置kafka.props 本环节配置时把注释都去掉,ogg不识别注释,如果不去掉会报错!!!
1 2 cd /data/ apps/ogg/ dirprm/ vim kafka.props
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # handler类型 gg.handlerlist=kafkahandler gg.handler.kafkahandler.type=kafka # Kafka生产者配置文件 gg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer.properties # kafka的topic名称,无需手动创建 # gg.handler.kafkahandler.topicMappingTemplate=test_ogg(新版topicName属性的设置方式) gg.handler.kafkahandler.topicName=test_ogg # 传输文件的格式,支持json,xml等 gg.handler.kafkahandler.format=json gg.handler.kafkahandler.format.insertOpKey = I gg.handler.kafkahandler.format.updateOpKey = U gg.handler.kafkahandler.format.deleteOpKey = D gg.handler.kafkahandler.format.truncateOpKey=T gg.handler.kafkahandler.format.includePrimaryKeys=true # OGG for Big Data中传输模式,即op为一次SQL传输一次,tx为一次事务传输一次 gg.handler.kafkahandler.mode=op # 类路径 gg.classpath=dirprm/:/data/apps/kafka_2.11-0.11.0.1/libs/*:/data/apps/ogg/:/data/apps/ogg/lib/*
紧接着创建Kafka生产者配置文件:
1 vim custom_kafka_producer .properties
添加以下内容:
1 2 3 4 5 6 7 8 9 10 11 # kafkabroker的地址 bootstrap.servers=cdh01:9092,cdh02:9092,cdh03:9092 acks=1 # 压缩类型 compression.type=gzip # 重连延时 reconnect.backoff.ms=1000 value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer batch.size=102400 linger.ms=10000
配置时把注释都去掉,ogg不识别注释,如果不去掉会报错!!!
添加trail文件到replicate进程 1 2 GGSCI (cdh02) 1> add replicat rekafka exttrail /data/apps/ogg/dirdat/to,checkpointtable test_ogg.checkpoint 控制台显示的内容:REPLICAT added.
测试 启动所有进程 在源端和目标端的OGG命令行下使用start [进程名]的形式启动所有进程。
1 2 3 start mgrstart extkafkastart pukafka
目标端
可以通过info all 或者info [进程名] 查看状态,所有的进程都为RUNNING才算成功
1 2 3 4 5 6 7 GGSCI (ambari.master.com) 5> info all Program Status Group Lag at Chkpt Time Since Chkpt MANAGER RUNNING EXTRACT RUNNING EXTKAFKA 04:50:21 00:00:03 EXTRACT RUNNING PUKAFKA 00:00:00 00:00:03
目标端
1 2 3 4 5 6 GGSCI (ambari.slave1.com) 3> info all Program Status Group Lag at Chkpt Time Since Chkpt MANAGER RUNNING REPLICAT RUNNING REKAFKA 00:00:00 00:00:01
异常解决 如果有不是RUNNING可通过查看日志的方法检查解决问题,具体通过下面两种方法
或者ogg命令行,以rekafka进程为例
1 GGSCI (cdh02 ) 2 > view report rekafka
测试同步更新效果 现在源端执行sql语句
1 2 3 4 5 6 7 conn test_ogg/test_ogg insert into test_ogg values (3 ,'test' ,null );commit ;update test_ogg set name ='zhangsan' where id =3 ;commit ;delete test_ogg where id =3 ;commit ;
查看源端trail文件状态
1 2 ls -l /oracledata/ data/ogg/ dirdat/to* -rw-rw-rw- 1 oracle oinstall 1464 May 23 10 :31 /opt/ ogg/dirdat/ to000000
查看目标端trail文件状态
1 2 ls -l /data/ apps/ogg/ dirdat/to* -rw-r----- 1 root root 1504 May 23 10 :31 /opt/ ogg/dirdat/ to000000
查看kafka是否自动建立对应的主题
1 bin/kafka-topics.sh --list --zookeeper localhost:2181
在列表中显示有test_ogg则表示没问题
1 2 3 4 bin/kafka-console -consumer.sh --bootstrap-server 192.168 .44 .129 :9092 --topic test_ogg --from -beginning {"table" :"TEST_OGG.TEST_OGG" ,"op_type" :"I" ,"op_ts" :"2019-08-17 22:04:39.001362" ,"current_ts" :"2019-08-17T22:04:44.610000" ,"pos" :"00000000010000001246" ,"primary_keys" :["ID" ],"after" :{"ID" :3 ,"NAME" :"test" ,"SEX" :null }} {"table" :"TEST_OGG.TEST_OGG" ,"op_type" :"U" ,"op_ts" :"2019-08-17 22:05:44.000411" ,"current_ts" :"2019-08-17T22:05:50.764000" ,"pos" :"00000000010000001541" ,"primary_keys" :["ID" ],"before" :{"ID" :3 ,"NAME" :"test" ,"SEX" :null },"after" :{"ID" :3 ,"NAME" :"zhangsan" ,"SEX" :null }} {"table" :"TEST_OGG.TEST_OGG" ,"op_type" :"D" ,"op_ts" :"2019-08-17 22:06:33.000312" ,"current_ts" :"2019-08-17T22:06:39.845000" ,"pos" :"00000000010000001670" ,"primary_keys" :["ID" ],"before" :{"ID" :3 ,"NAME" :"zhangsan" ,"SEX" :null }}
before代表操作之前的数据,after代表操作后的数据,现在已经可以从kafka获取到同步的json数据了,后面可以用SparkStreaming和Storm等解析然后存到hadoop等大数据平台里
注意事项 1 如果想通配整个库的话,只需要把上面的配置所有表名改为*,如test_ogg.test_ogg 改为 test_ogg.*,但是kafka的topic不能通配,所以需要把所有表的数据放在一个topic,后面再用程序解析表名即可。
1 若后期因业务需要导致表结构发生改变,需要重新生成源端表结构的defgen定义文件,再把定义文件通过scp放到目标端。defgen文件的作用是,记录了源端的表结构,然后我们再把这个文件放到目标端,在目标端应用SQL时就能根据defgen文件与目标端表结构,来做一定的转换。
参考资料 基于OGG的Oracle与Hadoop集群准实时同步介绍
Fusion Middleware Integrating Oracle GoldenGate for Big Data